Let me tell you about the most damning statistic I've ever seen in consumer research. 81% of consumers suspect that companies are training AI systems on personal data without clearly disclosing it. Eighty-one percent. Four out of five of your customers believe you're lying to them about what you do with their data.
And here's the thing that should terrify you: It doesn't matter if they're right.
The assumption of guilt is already baked in. You've been convicted in the court of public opinion before you even know you're on trial. Whether you're actually training AI on customer data without consent is almost irrelevant. Consumers have already decided you are.
And they're acting on that assumption.
The universal suspicion
When I saw this number, my first instinct was to segment it. Surely this is concentrated in certain demographics, right?
Nope. The suspicion is universal.

- Gen Z: 87%
- Millennials: 84%
- Gen X: 80%
- Boomers: 76%
- "Very comfortable" with AI: 85%
Even the oldest generation shows three-quarters suspicion. This isn't a generational divide. This is civilizational consensus.
And look at that last line: People who are "very comfortable" with AI (enthusiasts who actively seek it out): 85% suspect secret training.
The people who love your AI products most are the most suspicious you're misusing their data.
That's not ignorance breeding fear. That's informed skepticism. They know enough about how AI works to know that training on user data is valuable, possible, and often undisclosed.
So they assume you're doing it.
Why this matters more than any other trust issue
I've been through every major privacy scandal of the last decade. Cambridge Analytica. Equifax. Every GDPR fine.
Each time, consumers would express concern in surveys, then continue using products exactly as before. Privacy concern was performative, not actual.
But AI training suspicion is different. For three reasons:
First: The stakes feel existential. When Meta used your data for ads, it was annoying. When a company might be training AI on your personal data, it feels like permanent loss of control. That data is now baked into a model forever, sold to anyone, used for purposes you can't imagine.
Second: The opacity is total. You could kind of understand cookies. But AI training? Where does your checkout data go when it "trains a model"? What does that mean? Consumers have zero mental model. And in absence of understanding, humans default to worst-case assumptions.
Third: The scandals keep proving them right. Every month there's a new story. OpenAI training on conversations. Midjourney trained on artists' work without permission. Each scandal confirms: "See? I knew they were doing it." Even if YOUR company isn't doing it, consumers assume you are.
The assumption of guilt problem
Here's what keeps me up at night about the 81%:
You can't disprove a negative.
How do you prove you're NOT secretly training on customer data? You can issue a press release saying "We would never!" But that's exactly what a company that IS doing it would say. You can update your privacy policy. But nobody reads those.
Consumers have heard promises before. They've been reassured before. And then they got breached. Or the company was selling data they said they weren't. Or terms changed quietly.
Promises are worthless. Policies are worthless. Statements are worthless.
The only thing that has value is proof. Real-time, customer-facing, independently auditable proof that their data is NOT being used for training without consent.
And I'll bet $100 right now that your company can't provide that proof. Not because you're doing anything wrong. But because you haven't built the systems that make proof possible.
You've been operating on the assumption that privacy is about promises. But the market has moved to proof. And you don't have it.
The breach experience multiplier
Want to know who's most suspicious?
People who've been breached before: 88%.
And here's the punch line: 53% of all consumers have been breached. Over half your customer base has direct experience with companies failing to protect data.
They got the letter. They checked if their credit card was stolen. They set up fraud alerts. They changed 47 passwords. They spent hours on hold with banks.
That experience teaches you something: Companies cannot be trusted to do what they say they'll do with your data.
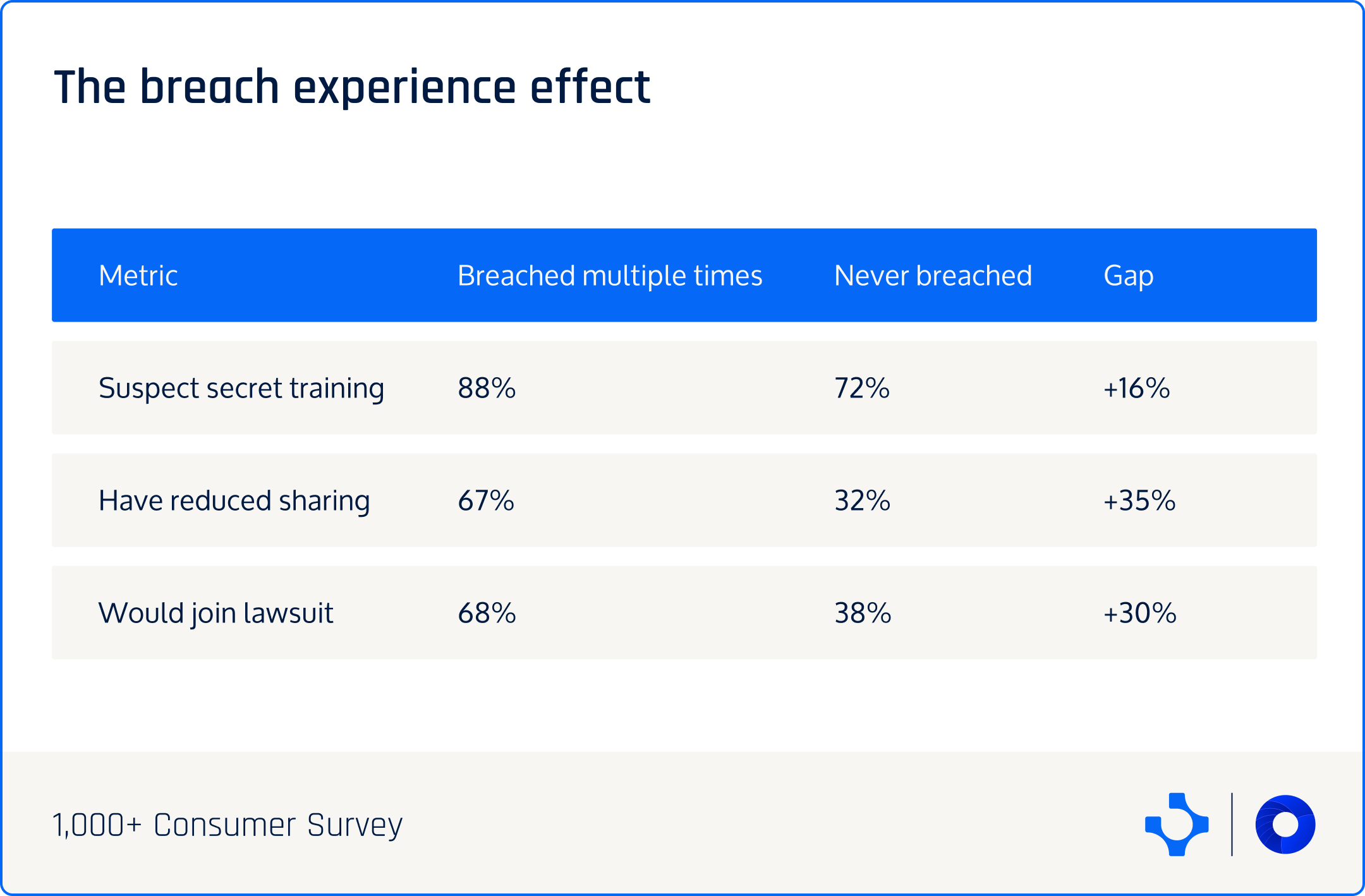
Once you've been burned, you approach every data collection with suspicion. And once you're suspicious, you start noticing things.
"Why does this app need my contacts?"
"Why does this website want my birthday?"
"What are they REALLY doing with this data?"
And the answer you arrive at, 88% of the time: "They're training AI on it without telling me."
The AI paradox: Understanding breeds suspicion
This finding broke my mental model.
I assumed: People who understand AI better will trust AI more.
I was completely wrong.
People who are "very comfortable" with AI: 85% suspect secret training. People who are "uncomfortable" with AI: 81% suspect.
The most AI-fluent users are MORE suspicious, not less.
Why?
Because when you understand AI, you know:
- Training data is the most valuable asset
- More data equals better models
- User data is abundant and high-quality
- Scraping it is technically easy
- Getting permission is legally complicated
- Many companies are doing it
If you're building AI products, user data is incredibly tempting. It's sitting right there. It would make your models so much better.
So people who understand AI think: "Of course they're using it. Why wouldn't they? I would if I were them."
The suspicion isn't born from ignorance. It's born from understanding the incentives.
The 37% who want proof you're NOT training
When we asked what matters MOST about AI transparency, the top answer was:
37% said "Proving my data isn't used for training without permission."
Not "showing where data goes" (36%, essentially tied). Not "detecting misuse" (17%).
The number one thing consumers want is proof that you're NOT doing the thing they assume you're doing.
This is backwards from every other customer need I've researched.
Usually: "Prove your product works." "Prove you're faster." "Prove you're secure."
But here: "Prove you're NOT doing the bad thing we assume you're doing."
That's not a feature request. That's a presumption of guilt you have to actively overcome.
And it's not enough to say "We don't train on customer data without consent." Because every company says that, and 81% don't believe any of you.
You need to SHOW it. Real-time. Customer-facing. Independently auditable.
"Here's your data. Here's the AI systems that process it. Here's proof it went to inference, not training. Here's the timestamp of deletion. Here's the third-party audit."
Anything less, and you're just another company making promises that 81% assume are lies.
The competitive opportunity hiding in suspicion
Here's the silver lining: The 81% who suspect secret training aren't anti-AI. They're anti-opacity.
They're not saying "I'll never use AI products." They're saying "I assume you're misusing my data unless you prove otherwise."
That's an enormous opportunity.
Because if everyone assumes you're guilty, the company that can prove innocence has a massive competitive advantage.
Imagine being the first company in your category to show customers (not tell them, SHOW them) that their data is NOT being used for training without consent.
"Here's the dashboard. Here's your data. Here's the journey through our systems. Here's proof it went to inference only. Here's the audit trail. Here's third-party verification."
You'd be the only one. The ONLY company in your space that could credibly make that claim and back it up.
And what happens to market share when 81% suspect everyone EXCEPT you?
The three levels of response
Most companies will do one of three things:
Level 1: Ignore it.
"Our customers aren't that sophisticated. They don't really care."
Bad move. The suspicion is universal and higher among your most valuable customers. Ignoring it is how you wake up and realize your AI models are degrading because customers quietly reduced data sharing.
Level 2: Promise better.
"We'll update our privacy policy. We'll issue a statement. We'll make commitments."
Slightly better, but insufficient. Promises don't work when 81% don't believe you. You're fighting assumption with assertion. You'll lose.
Level 3: Prove it.
"We'll build systems that let customers see exactly where their data goes and verify it's not used for training without consent. Real-time. Customer-facing. Independently audited."
This is the only response that works. Because it doesn't fight suspicion with promises. It fights suspicion with proof.
And proof is the only currency that 81% will accept.
Why this matters more than you think
The 81% who suspect secret training aren't just worried. They're changing behavior:
- 51% have reduced data sharing
- 54% have avoided AI features
- 57% would stop using your product if you admitted opacity
- 52% would join legal action if you can't trace data flows
The suspicion has teeth. It's not abstract. It's active retaliation.
And here's the thing: You probably deserve the suspicion.
Not because you're secretly training on customer data (though some of you are). But because you can't PROVE you're not. And in 2025, if you can't prove it, you might as well be doing it.
The burden of proof has flipped. It used to be: "Innocent until proven guilty." Now it's: "Guilty until proven innocent."
81% have made up their minds. The only question is: Can you change them with proof?
Or will you keep making promises that nobody believes?
—————
About the Survey: The data in this post was collected by TrueDotᴬᴵ conducted in December 2025 surveying 1,017 U.S. consumers. You can download the full report “The AI Data Ultimatum” here.


